Benchmarking
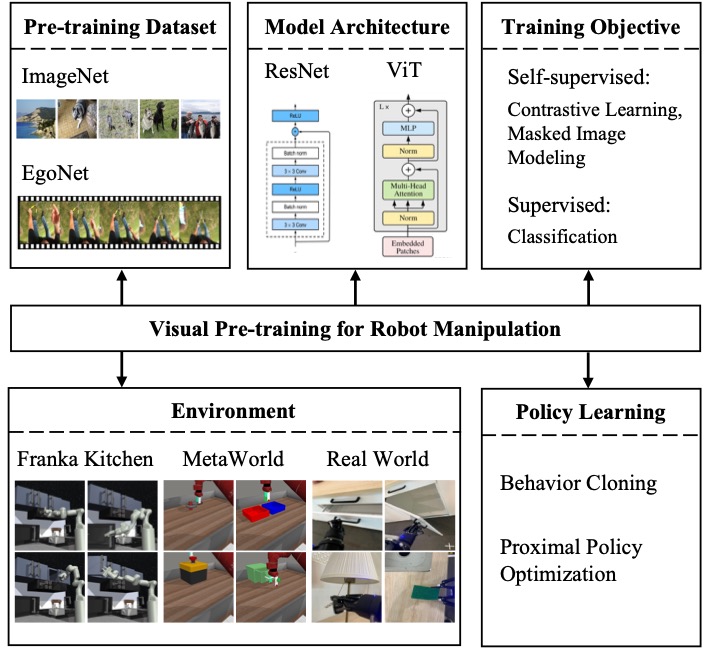
We conduct extensive studies on visual pre-training from three fundamental aspects: datasets, models and methods that may influence the performance of robot learning. To facilitate the fundamental studies, we also propose a new dataset named EgoNet, which is created based on Ego4d and contains a large-scale egocentric video clips rich in human-object interactions. EgoNet has the potential to serve as a benchmark to pre-train visual models for robot manipulations. Through the explorations on various pre-training datasets, model architectures and pre-training methods, three key conclusions could be drawn: (1) Visual pre-training with human-object interaction data is of great importance for robot manipulation. (2) Convolution-based ResNet-50 is preferred in retaining visual knowledge for robot manipulation. (3) The sequential pattern and semantic information learned by contrastive learning are more effective.

Approach
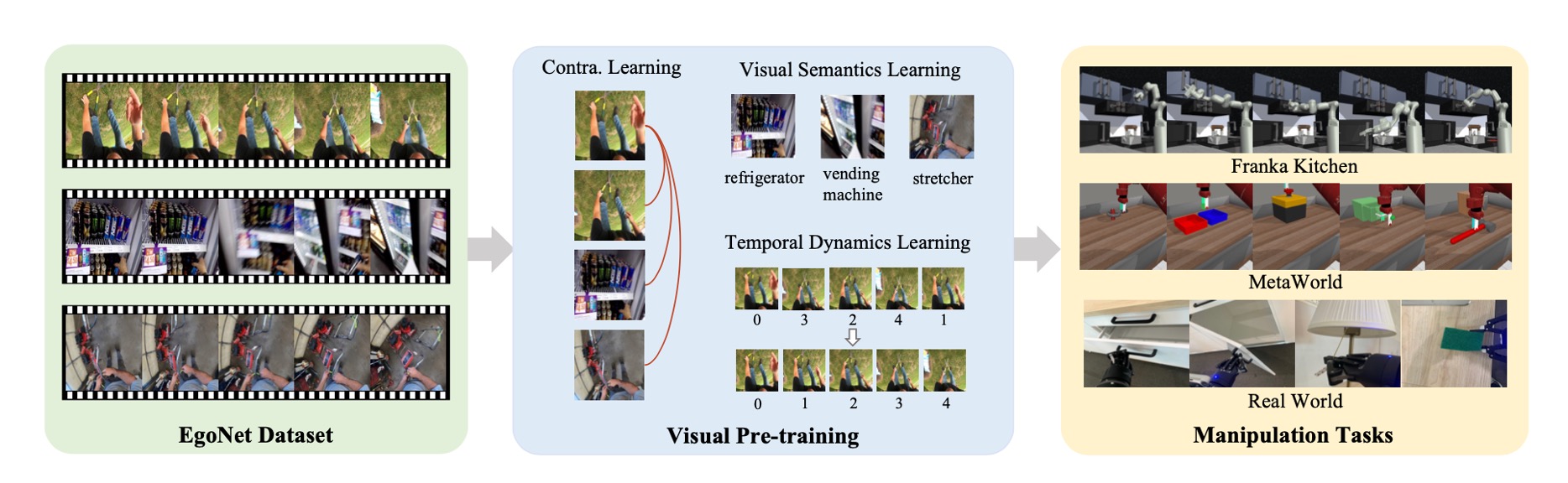
Based on empirical findings, we propose a visual pre-training scheme termed Vi-PRoM for robot manipulations, which sequentially trains a visual encoder using self-supervised learning and supervised fine-tuning. Concretely, the visual encoder is first pre-trained based on contrastive learning, allowing the trained model to acquire sequential patterns implicitly for the input data. Then, supervised learning is applied by constructing pseudo-labels and temporal labels to encourage the visual encoder further to perceive visual semantics and temporal dynamics.
Results
Vi-PRoM achieves the best performance in both simulation environments. In addition, the performance gains of
our Vi-PRoM over the MoCo-v3, reaching 3.3% and 2.3% in success rate in Franka Kitchen and MetaWorld, respectively,
indicate the value of explicitly learning visual semantics and temporal dynamics. In addition, the success rate of
Vi-PRoM improves steadily as the size of the demonstration data increases.
Vi-PRoM achieves the best performance in both simulation environments. In addition, the performance gains of our Vi-PRoM over the MoCo-v3, reaching 3.3% and 2.3% in success rate in Franka Kitchen and MetaWorld, respectively, indicate the value of explicitly learning visual semantics and temporal dynamics. In addition, the success rate of Vi-PRoM improves steadily as the size of the demonstration data increases.

Related Links
BibTeX
@inproceedings{jing2023explore
author = {Ya Jing, Xuelin Zhu, Xingbin Liu, Qie Sima, Taozheng Yang, Yunhai Feng, Tao Kong},
title = {Exploring Visual Pre-training for Robot Manipulation: Datasets, Models and Methods},
booktitle = {2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2023}
}